

Deep Learning bei flying dog im Jahr 2017.
Spannende Projekte von Bilderkennung bis hin zur Textanalyse
Im Interview mit NBC bezeichnete Google-CEO Sundar Pichai Künstliche Intelligenz als eine der wichtigsten Entwicklungen der Menschheit. Die Technologie sei grundlegender als Feuer oder Elektrizität.
Wie sehr Künstliche Intelligenz den Werdegang der Menschheit verändern wird, können
wir nicht sagen.
Wir sehen aber ein großes Potential - vielleicht sogar eine gewisse Notwendigkeit, um
nicht abgehängt zu werden - bei vielen unseren Kundenprojekten und Produkten.
Daher befassen wir uns seit Anfang 2017 intensiv mit diesen Technologien. Wir bauen in
diesem Gebiet das erforderliche Know-How auf, um hier Lösungen anzubieten.
Dabei handelte es noch ausschließlich um Testprojekte.
Hier ein sehr spannender Rückblick über unsere KI-Projekte in 2017:
Gesichtserkennung
Typischerweise dient die technische, computergestützte Gesichtserkennung als
Zutrittskontrolle zu sicherheitsempfindlichen Bereichen sowie zur Suche nach
Dubletten in Datenbanken, beispielsweise in Melderegistern zur Vermeidung von
Identitätsdiebstahl.
Man kennt diese Verfahren aber auch aus Programmen zur Verwaltung von Fotos
(insbesondere auf Smartphones) oder aus Social Networks wie z.B. Facebook, wobei
automatisch bei einem Foto die Gesichter bzw. Personen erkannt werden.
Die führende Software auf diesem Gebiet - DLib - bietet eine Genauigkeit von 99,38%,
d.h. etwa eine von über hundert Personen wird nicht erkannt.
Wir haben hier den Datenbestand eines Kunden, welcher intensiv Fotos von Personen
(u.a. Politiker) in der modernen Mediendatenbank von unserem ECMS Powerslave
verwaltet, zum Testen genommen. Dabei konnten wir diese sehr hohe Treffergenauigkeit
reproduzieren.
Dabei reichte nur ein einziges Foto einer Person aus, um diese überall korrekt zum
automatischen Tagging zu identifizieren.
Die Geschwindigkeit ist dabei sehr hoch und dieses Verfahren kann auch auf Videos
angewendet werden.
Text-Klassifikation von Tickets im Service-Desk
Für einen Service-Desk wird in der Regel eine Kontakt-Email Adresse angeben. In der Ticketbearbeitung hingegen arbeiten die Supporter durchaus in unterschiedlichen Gruppen an diesen Support-Anfragen. So sind für einen innerbetrieblichen Helpdesk eines größeren Unternehmens z.B. Gruppen wie Arbeitsplatzrechner, Software, Mobile Geräte, etc denkbar. Bei einem Helpdesk, der sich an die Kunden eines Unternehmens richtet, können die Gruppen z.B. unterschiedliche Produktlinien widerspiegeln. Damit nicht jede Anfrage erst manuell in eine dieser Gruppen gelegt werden muss, hilft eine automatische Klassifikation anhand des Inhalts der Anfrage. Für diesen Test haben wir 45000 Tickets, welche uns ebenfalls freundlicherweise zu Testzwecken zur Verfügung gestellt worden sind, in 200 Kategorien klassifiziert. Als Tool haben wir fastText genommen. Hierbei hat uns die Geschwindigkeit zum Anlernen überrascht. Die Trainingsphase aller 45000 Tickets dauerte dabei nur wenige Sekunden. Die Ergebnisse sind trotz der doch recht vielen Kategorien sehr gut.
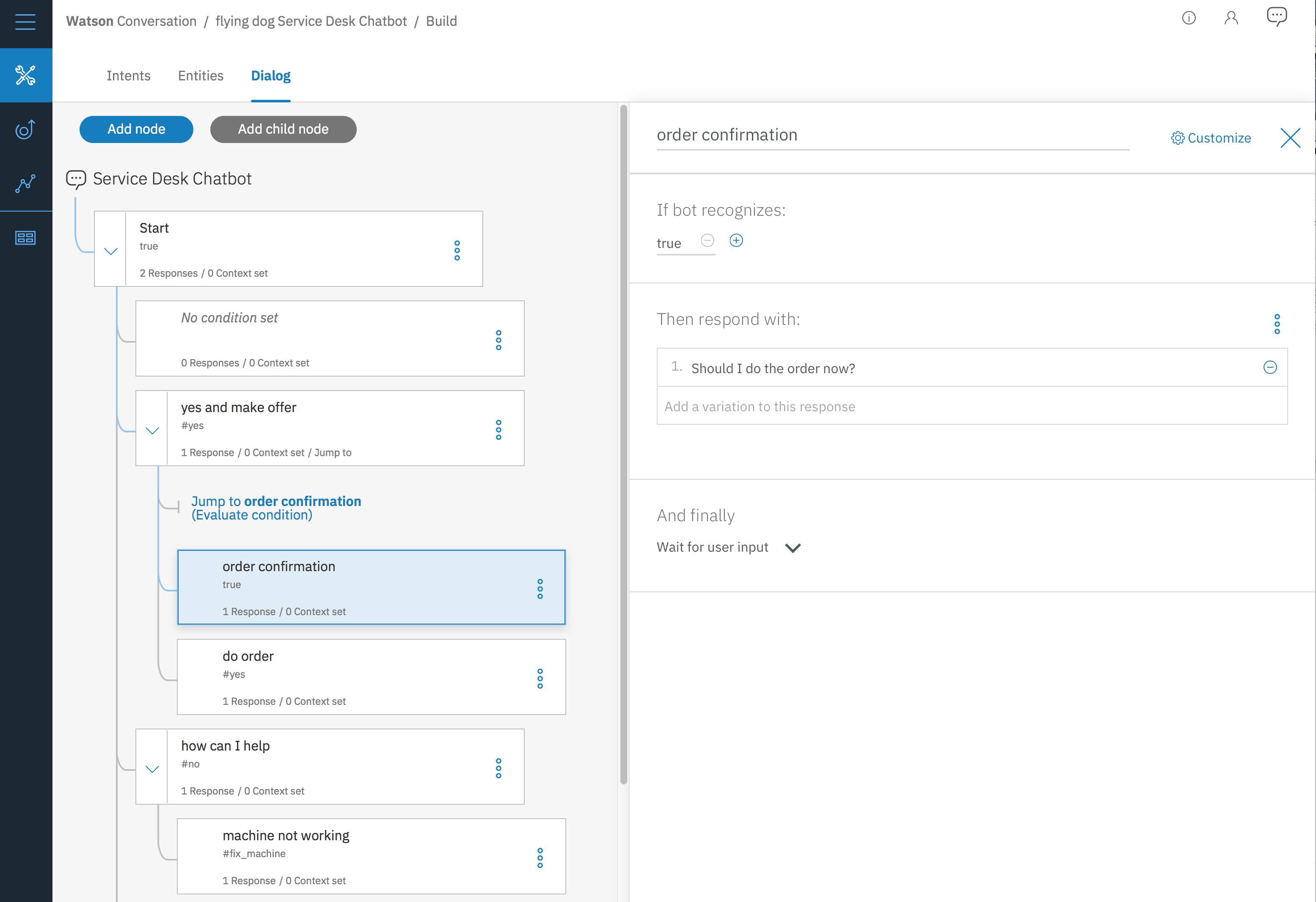
Chatbot auf Basis von IBM Watson Conversation
Für einen Maschinenbau-Hersteller haben wir den Prototypen einer Kunden-Smartphone App entwickelt, welche einen sprachgesteuerten Chatbot integriert und an unserem Helpdesk angebunden wurde. Dieser Prototyp bestand zuerst aus statischen, also festen, Mockups. Parallel dazu haben wir einige Chat-Verläufe (Bestellung, Melden eines Problems) in IBM Watson Conversation umgesetzt. IBM Watson bietet hierfür vier wichtige Basis Bestandteile:
- Intents - also Absichten. Hier werden Beispiel-Anfragen des Kunden gesammelt. Also z.B. “Machine XY is not working anymore” oder “Our XY needs to be repaired”. Dabei können für XY konkrete Produkte eingesetzt werden, diese aber sind variabel, denn mit den
- Entities werden die möglichen Produkte inkl. unterschiedlichen Schreibweisen gesammelt. Das können bei einem Flugbuchungssystem Reiseziele sein oder hier die Produkte des Herstellers.
- Dialog: Hiermit werden mögliche Chatverläufe in einer Art Prozessdesigner erstellt. Das System nutzt also nur zur Texterkennung KI Techniken und legt die Absichten und Entitäten in Variablen ab. Diese können dann im vorgegebenen Ablauf verwendet werden, um Abzweigungen zu machen und z.B. weitere Fragen zu stellen.
In der Praxis steht so ein Chatbot nicht alleine. Es werden unterschiedliche weitere Bausteine benötigt:
- eine schnelle OCR, um z.B. Typenschilder und damit die Seriennummer mit Hilfe der Smartphone-Kamera zu erkennen
- Schnittstellen zum Backend des Kunden mit einer Produkt-Datenbank inklusive möglichen Hilfestellungen/Problemen
- Spracheingabe und Ausgabe
- flying dog Helpdesk Integration und Übergabe zu einem Service Mitarbeiter aus Fleisch und Blut z.B. über Telefon
Zum Teil macht das dann den IBM Dialog-Designer hinfällig, und man sollte hier
bessere eigene Tools verwenden.
Vorträge zum Thema Deep Learning
Ich habe 2017 bei einer Hochschule und bei einem Kunden Einführungsvorträge zum Thema Deep Learning gehalten. Dabei wurden folgende Themen betrachtet:
- Deep Learning und KI als disruptive Technologie mit sehr großen gesellschaftlichen Auswirkungen
- Ursachen für den Durchbruch
- die wichtigsten Tools (Hard- und Software) für die Umsetzung eigener DL Projekte
- die größten Hindernisse beim Einstieg in dieses Thema
- Live-Beispiel in der Bilderkennung (Inception V3)
- Live-Training: Bilderkennung mittels eines neuronalen Netzes auf einem sehr leistungsfähigen Remote-Computer
- Grundlagen neuronaler Netze: biologischer Ansatz
- Grundlagen neuronaler Netze: mathematischer Ansatz
- Beispiele für Klassifikation und Regression anhand von tabellarischer Daten
- Eine Übersicht zu weitergehenden Themen wie CNN, LSTM, Keras
- Beispiel: Textanalyse mit IBM Watson
Der Vortrag wurde dabei mit realen vorher selbst erstellten Beispielen abgerundet, so z.B. das Erkennen von Automarken anhand von beliebigen Fotos oder eine Textanalyse (Erfassung von Stimmungen, Emotionen, Kategorien etc.) mit IBM Watson Natural Language Understanding.
Installation von Deep Learning Umgebung, Hardwarekosten sind deutlich gestiegen
In 2017 haben wir eine vollständige Installation eines Deep Learning Systems inkl. Hardware Unterstützung durchgeführt. Leider sind die Tools teilweise umständlich zu installieren. Auch müssen zum Teil aus Quellcode Libraries neu kompiliert werden. Auf der Hardwareseite sind moderne Grafikkarten von NVIDIA der zentrale Bestandteil. Es gibt zur Zeit noch kein Konkurrenzprodukt am Markt, so dass hier eine Art Monopol entstanden ist. Das hat sich in den geänderten Lizenzbedingungen so ausgewirkt, dass NVIDIA die Nutzung der leistungsfähigen Geforce Karten (z.B. 1080 Ti) in Rechenzentren Ende 2017 für Deep Learning Projekte untersagt hat. Die alternativen Tesla Karten liegen etwa beim 4-5-fachen Preis. Für die Nutzung auf Einzelplatzrechner gibt es immerhin keine Einschränkungen.
Diese Hardware Anforderungen sind nicht für alle Deep Learning Projekte notwendig. So z.B. können die oben genannten Gesichtserkennung oder Texterkennung auf den üblichen Linux Virtual Machines im VMWare Fusion ESX Umfeld genutzt werden.
Interessante Fortschritte in der Robotik
Mit Hilfe von neuen Strategien im sogenannten Reinforcement Learning sind dem Google Deepminds Team 2017 große Fortschritte in der Simulation von Robotern gelungen. Kurz darauf wurden diese Verfahren mit Unterstützung des OpenAI Teams verfeinert, z.B. um die angelernten Modelle robuster auf reale Umgebungen zu übertragen (Generalizing from Simulation). Da die Robotik kein Thema der flying dog software ist, haben wir das nur am Rande beobachtet. Trotzdem eine Anmerkung: mit Hilfe dieser Entwicklungen, der ebenfalls neuen HoME Plattform und neuen Tiefensensoren (z.B. die 400er Serie von Intel) sollten in absehbarer Zeit Laufroboter in unsere Haushalte Einzug halten.
Vollständig eigene Entwicklung von Deep Learning Projekten
Neben der Nutzung von vorhandenen Deep Learning Modellen wie in den Kapiteln oben, haben wir uns auch mit dem vollständigen Neuaufbau von eigenen Netzen beschäftigt. Während dies für vorhandene tabellarische Daten nach einer guten Aufbereitung durchaus machbar ist, kann es bei weitergehenden Anforderungen ziemlich kompliziert werden. Wir sind im Deep Learning Bereich auch wesentlich mehr auf Kundendaten als sonst üblich bei unserer Produkt- oder Projektentwicklung angewiesen. Die Hardware und Projektkosten liegen schnell bei einem Vielfachen sonst üblicher Softwareprojekte. Hier sind viele Faktoren zu berücksichtigen: gute Datenbasis zum Anlernen, passende leistungsfähige Hardware, Finden eines passenden Netzes (z.B CNN bei Bilderkennung, LSTM bei Textanalyse) und geeigneter Hyperparameter (Anzahl der Knoten, Tiefe etc.). Hier können schnell Wochen Entwicklungszeit ohne gute Ergebnisse vergehen.
Yolo - flying dog or dog
Ein Projekt, welches inzwischen in unterschiedlichen Produkten verwendet wird, die z.B. auf der CES 2018 vorgestellt worden sind, ist YOLO (You only look once). Mit diesem inzwischen auf Tensorflow-Basis erhältlichen Projekt lassen sich beliebige Objekte in Echtzeit in Videostreams erkennen. Neben YOLO sind die Tensorflow Object Detection API oder Detecron ähnlich interessante Projekte. Hier in diesem Beispiel werde ich als “person” und der Hund als “dog” über die eingebaute Webcam meines PC mit einem Standardmodell erkannt:
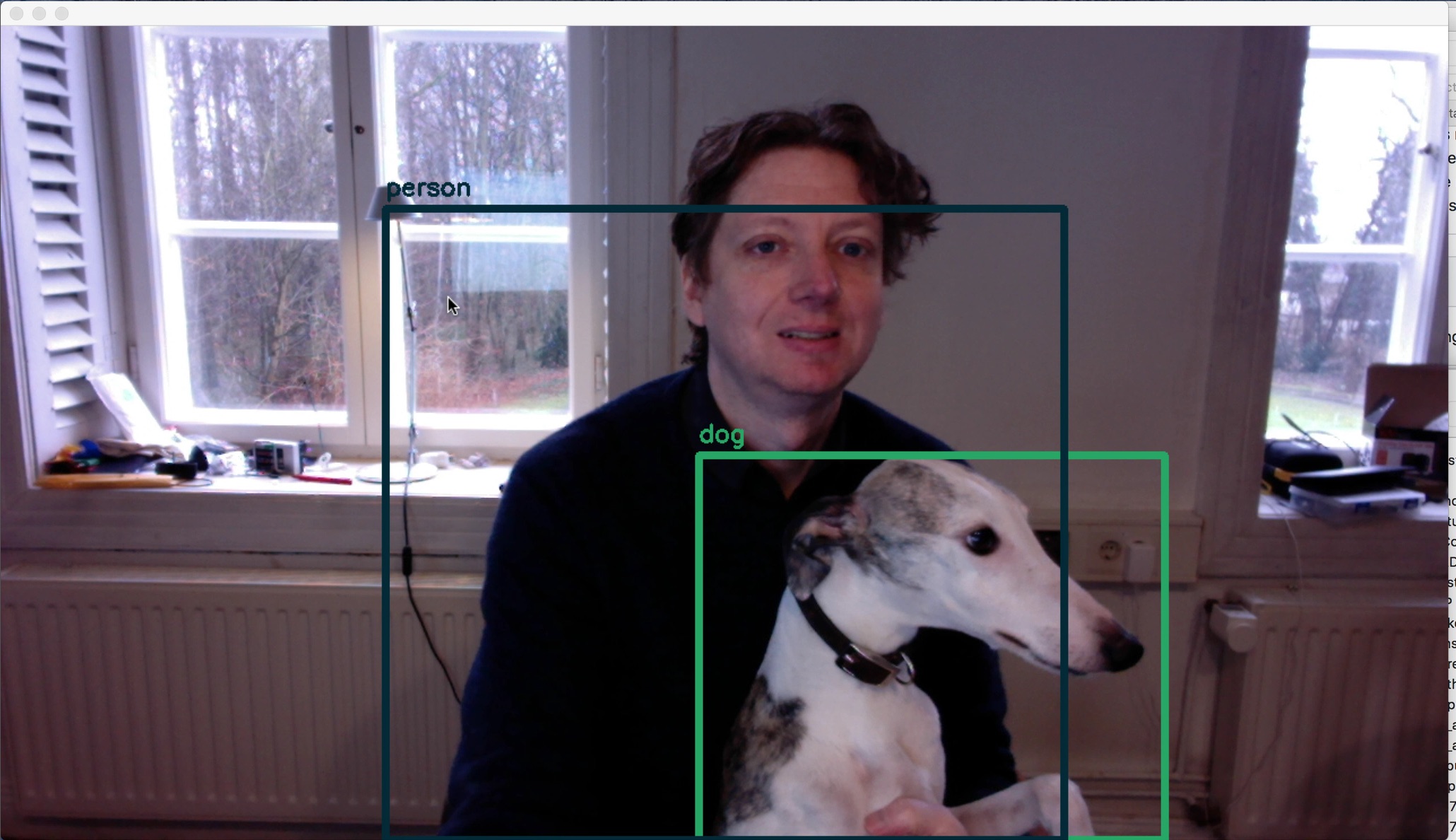
In Anlehnung an “Not Hotdog” haben wir die Erkennung von fliegenden Hunden erfolgreich angelernt:

Dabei haben wir folgende Dinge gelernt:
- Eine NVIDIA GPU ist hier notwendig, da sonst der Lernprozess Tage dauern kann.
- Der Datenbestand sollte ausreichend groß sein. Eine Datensatz mit 10 Fotos hat keine erkennbaren Ergebnisse erzielt. Erst als dieser auf ca. 60 Fotos erweitert worden ist, wurde die Erkennung ziemlich gut.
- Beim Anlernen ist dabei das bei Deep Learning bekannte "Overfitting"-Problem aufgetreten. Dieses hatte die Erkennungsrate erstmal negativ beeinflusst.
